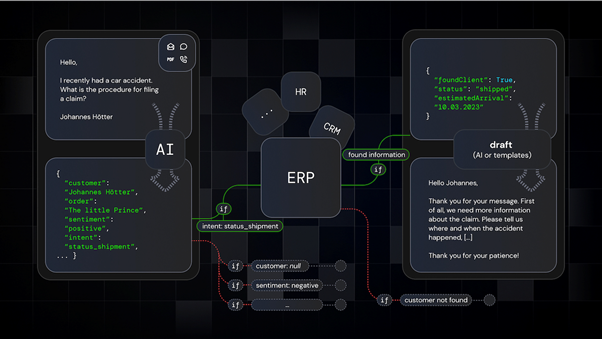
テキストや文書のAIに取り組むデータサイエンスチームの多くは、通常、構築できるものが制限されています。ドメインエキスパートと共に仕事をする際は、主にExcelファイルの共有を通じて行われ、遅いアノテーション(データにタグを付ける作業のこと)と透明性のないデータ決定につながります。
Kern AIは、大規模な言語モデルを使用することで、テキストやドキュメントを生成することに特化しています。Kern AIを使えば、エンジニアはデータ作業の60〜70%を簡単に自動化でき、非常に複雑なサンプルもプラットフォーム内で共同作業できます。Kern AIは、スケーラブルな社内トレーニングデータエンジンにより、標準化されていないプロセスの自動化を支援します。例えば、スキャンしたPDFや電子メールからのデータ抽出、保険金請求や契約書の個人情報の再編集と分類、大規模な言語モデルによる推論などです。これにより、複雑なプロセスに対して、限られた社内リソースだけで信頼性の高いカスタムアプリケーションを作成することができます。
Kern AIの仕組み
AIで業務プロセスを確実に自動化するためには、ロー生のデータではなく、高品質のトレーニングデータが必要です。保険会社には豊富なロー生データがありますが、学習用データの量は限られています。ロー生データをトレーニングデータにする唯一の方法は、数少ないドメインエキスパートの助けを借りることです。Kern AIは、このプロセスを効率的に拡張するために、エンジニアにAIの学習を自動化・組織化するツールを提供し、専門家の負担を軽減しつつ信頼性の高いモデルを社内で構築することができるようにします。
データは、ドキュメントのカテゴリや複雑さなど、価値あるメタデータが自動的に割り当てられることによってより高い効果が発揮されます。エンジニアは、データのどの部分が低品質でありボトルネックになっているか監視し、一緒に調査するエキスパートを割り当てることができます。
ITC DIA Europe 2023でKern AIを採用した理由
Kern AIは、ChatGPTのようなテクノロジーと同様に、テキストとドキュメントのAIを提供する会社です。ヨーロッパで設立されたKern AIは、データの機密性が常に最優先される環境で成長し、それは今でもKern AIの技術やセキュリティの調整への対応の中心となっている。
ITC DIA Europe(ヨーロッパ最大のInsurTechのイベント)では、Kern AIのCEOであるヨハネス・ホッターがShow & Tellのステージに立ち、保険会社に関連するユースケースを紹介し、ChatGPTに類似する技術を安全な環境で、大規模に、そしてどのような用途で展開できるかを実証する予定です。
Kern AIとはどんな会社であるか
Kern AIは、ヨハネス・ホッターとヘンリック・ウェンクによって2020年に設立されました。ヨハネスとヘンリックは以前、一緒にAIコンサルタント会社を立ち上げ、天気予報やデータベースチャットボットなどのプロジェクトに携わってきました。
Kern AIは2年半の開発期間を経て、オープンソースコミュニティによって世界的に広く利用されています。この製品は、ドイツの保険会社と協力した研究プロジェクトとして始まり、開発者コミュニティによって世界的に採用されています。Kern AIは現在、ドイツの複数の保険会社とも連携し、信頼性の高いAIプロセスの構築を支援しています。
Kern AIは、ドイツのボンとベルリンに拠点を置いています。彼らは2022年12月に、ヨーロッパのVCであるSeedcampとFaber VCの共同主導で、270万ユーロ(2022年12月当時のユーロ円レートで換算すると3.8億円)のシード資金を調達しました。Kern AIは、ドイツのInsurLabプログラムも卒業しています。

CEOのJohannes Hötter
Kern AIでは、テキスト・ドキュメントAIを総合的に捉えています。AIの信頼性を高めているデータから、組織の制約まで。これは私たちが自信を持ち、手助けできる領域です。

Kern AIのチーム
※本記事は、https://www.digitalinsuranceagenda.com/featured-insurtechs/kern-ai-applying-chatgpt-like-capabilities-for-confidential-data/ を翻訳したものになります。